
You may see this kind of pair of images below before. Images are segmented by color based on the objects on them. They are called “semantic segmentation”. It is studied by many AI researchers now because it is critically important for self-driving car and robotics.
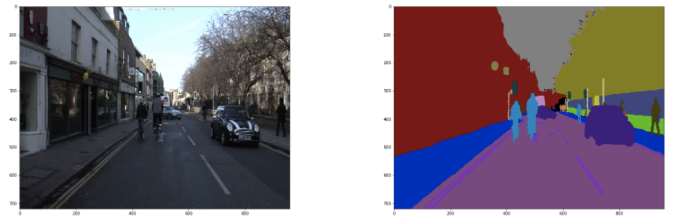
Unfortunately, however, it is not easy for startups like us to perform this task. Like other computer vision tasks, semantic segmentations needs massive images and computer resources. It is sometimes difficult in tight-budget projects. In case we cannot correct many images, we are likely to give it up.
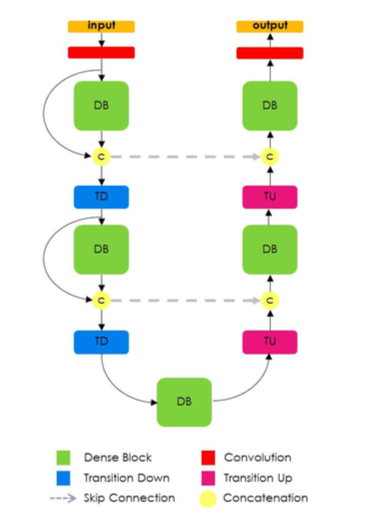
This situation can be changed by this new algorithm. This is called “Fully convolutional DenseNets for semantic segmentation (In short called “Tiramisu” 1)”. Technically, this is the network which consists of many “Densenet(2)”, which in July 2017 was awarded the CVPR Best Paper award. This is a structure of this model written in the research paper (1).
I would like to confirm how this model works with a small volume of images. So I obtain urban-scene image set which is called”CamVid Database (3)”. It has 701 scene images and colour-labeled images. I choose 468 images for training and 233 images for testing. This is very little data for computer vision tasks as it usually needs more than 10,000-100,000 images to complete training for each task from scratch. In my experiment, I do not use pre-trained models. I do not use GPU for computation, either. My weapon is just MacBook Air 13 (Core i5) just like many business persons and students. But new algorithm works extream well. Here is the example of results.
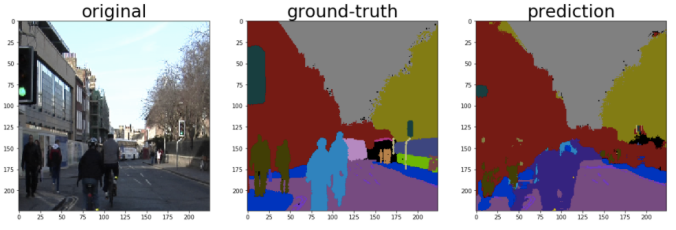
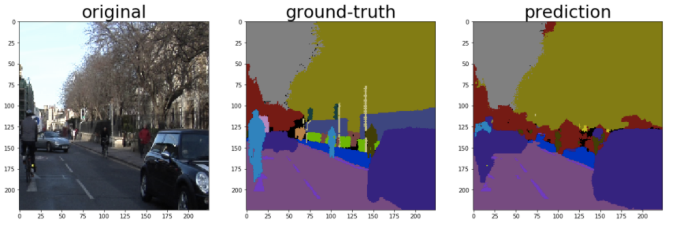
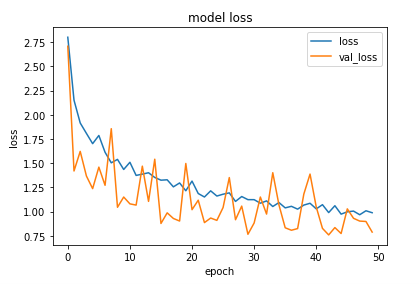
“Prediction” looks similar to “ground-truth” which means the right answer in my experiment. Over all accuracy is around 83% for classification of 33 classes (at the 45th epoch in training). This is incredible as only little data is available here. Although prediction misses some parts such as poles, I am confident to gain more accuracy when more data and resources are available. Here is the training result. It took around 27 hours. (Technically I use “FC-DenseNet56”. Please read the research paper(1) for details)

Added on 18th August 2017: If you are interested in code with keras, please see this Github.
This experiment is inspired by awesome MOOCs called “fast.ai by Jeremy Howard. I strongly recommend watching this course if you are interested in deep learning. No problem as it is free. It has less math and is easy to understand for the people who are not interested in Ph.D. of computer science.
I will continue to research this model and others in computer vision. Hope I can provide updates soon. Thanks for reading!
1.The One Hundred Layers Tiramisu: Fully Convolutional DenseNets for Semantic Segmentation (Simon Jegou, Michal Drozdzal, David Vazquez, Adriana Romero, Yoshua Bengio), 5 Dec 2016
2. Densely Connected Convolutional Networks(Gao Huang, Zhuang Liu, Kilian Q. Weinberger, Laurens van der Maaten), 3 Dec 2016
3. Segmentation and Recognition Using Structure from Motion Point Clouds, ECCV 2008
Brostow, Shotton, Fauqueur, Cipolla (bibtex)
Notice: TOSHI STATS SDN. BHD. and I do not accept any responsibility or liability for loss or damage occasioned to any person or property through using materials, instructions, methods, algorithm or ideas contained herein, or acting or refraining from acting as a result of such use. TOSHI STATS SDN. BHD. and I expressly disclaim all implied warranties, including merchantability or fitness for any particular purpose. There will be no duty on TOSHI STATS SDN. BHD. and me to correct any errors or defects in the codes and the software
