Since BERT was released from Google in Oct 2018, there are many models which improve original model BERT. Recently, I found ALBERT, which was released from Google research last year. So I perform small experiments about ALBERT. Let us make sentiment analysis model by using IMDB data. IMDB is movie review data, including review content and its sentiment from each user. I prepare 25000 training and 3000 test data. The reslut is very good. Let us see more details.
- It is easy to train the model as it has less parameters than BERT does.
BERT is very famous as it keeps good perfomance for NLP (natural language processing) tasks. But for me, it is a little too big. BERT has around 101 millions parameters. It means that it takes long to train the model and sometimes go over the capacity of memory of GPUs. On the other hand, ALBERT has around 11 millions so easy to train. It takes only about 1 hour to reach 90% accuracy when NVIDIA Tesla P100 GPU is used. It is awsome!


In this expriment, max_length is 256 for each sample
2. It is very accurate with a little data
ALBERT is not only fast to learn but also very accurate. I used pre-trained ALBERT base model from TensorFlow Hub. Because it is pretrained in advance, ALBERT is accurate with less data. For example, with only 500 training data, its accuracy is over 80%! It is very good when we apply it into real problems as we do not always have enough training data in practice.

max_length is 128 for each sample.
3. It is easily integrated to TensorFlow and keras
Finally, I would like to pointout ALBERT is easy to integrate TensorFlow keras, which is the framework of deep learning. All we have to do is to import ALBERT as “keras layer”. If you want to know more, check TensorFlow Hub. It says how to do it. I use TensorFlow keras everyday so ALBERT can be my favorate model automatically.
As I said, ALBERT is released in TensorFlow Hub and is free to use. So everyone can start using it easily. It is good to democratise “artificial intelligence”. I want to apply ALBERT into many applicatons in real world. Stay tuned!
Cheers Toshi
Notice: ToshiStats Co., Ltd. and I do not accept any responsibility or liability for loss or damage occasioned to any person or property through using materials, instructions, methods, algorithms or ideas contained herein, or acting or refraining from acting as a result of such use. ToshiStats Co., Ltd. and I expressly disclaim all implied warranties, including merchantability or fitness for any particular purpose. There will be no duty on ToshiStats Co., Ltd. and me to correct any errors or defects in the codes and the software

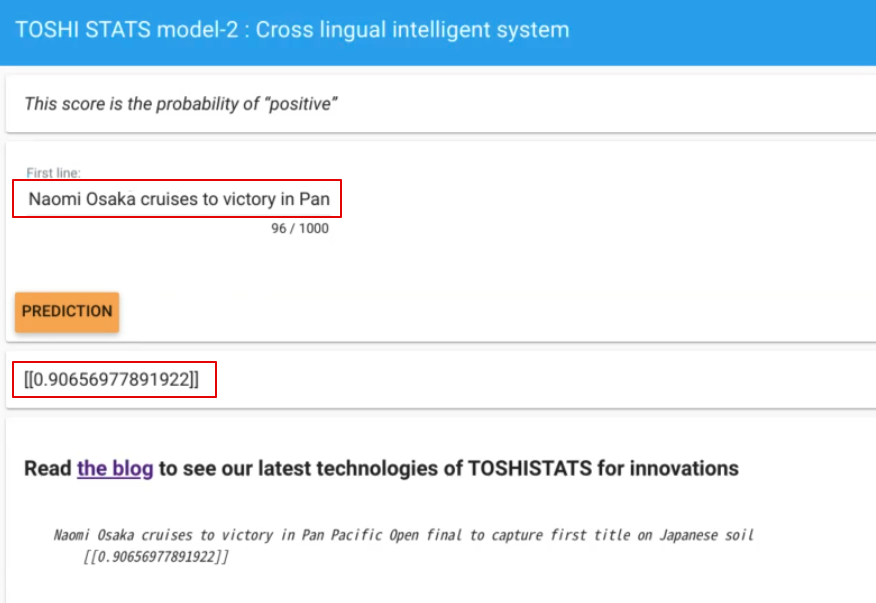
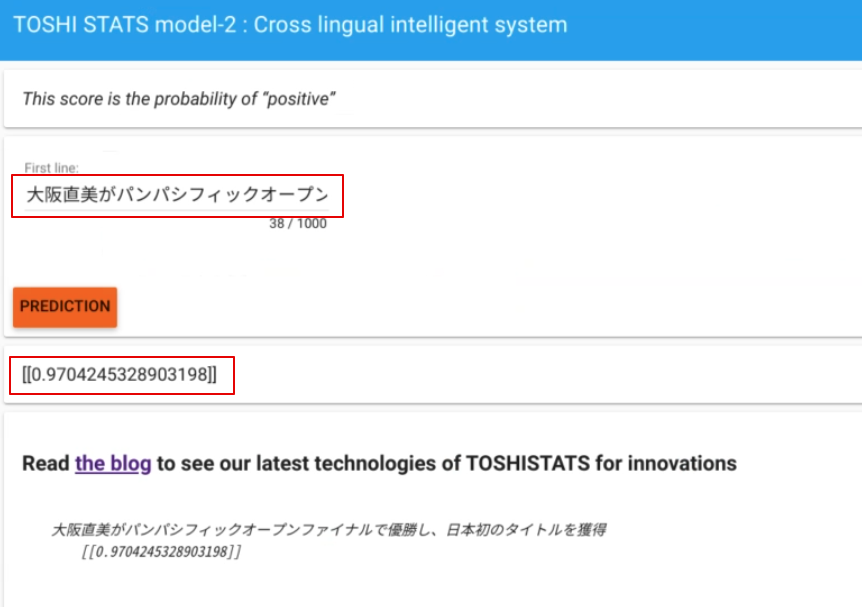
 This English sentence is translated into other 15 languages by Google translation. Then each sentence is input to the system and we measure “probability of positive sentiment”. Here is the result. 90% of them are over 0.8. It means that in most languages, the system can recognize each sentence as definitely “positive”. This is amazing! It works pretty well in 16 languages although the model is trained only in English.
This English sentence is translated into other 15 languages by Google translation. Then each sentence is input to the system and we measure “probability of positive sentiment”. Here is the result. 90% of them are over 0.8. It means that in most languages, the system can recognize each sentence as definitely “positive”. This is amazing! It works pretty well in 16 languages although the model is trained only in English.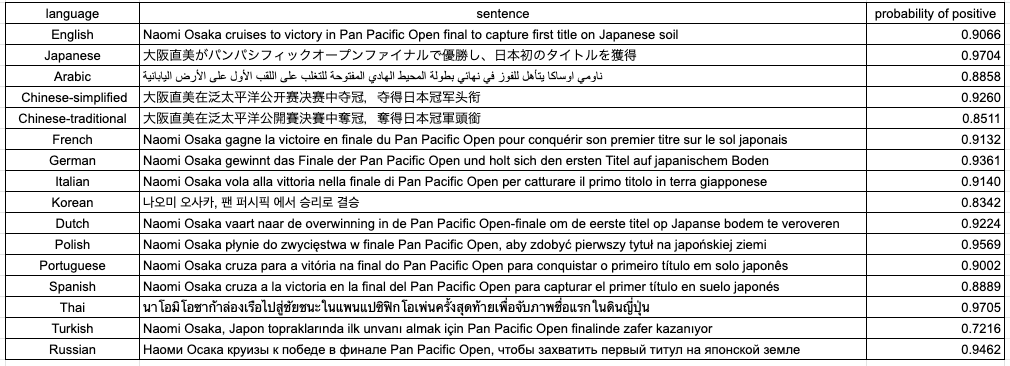
















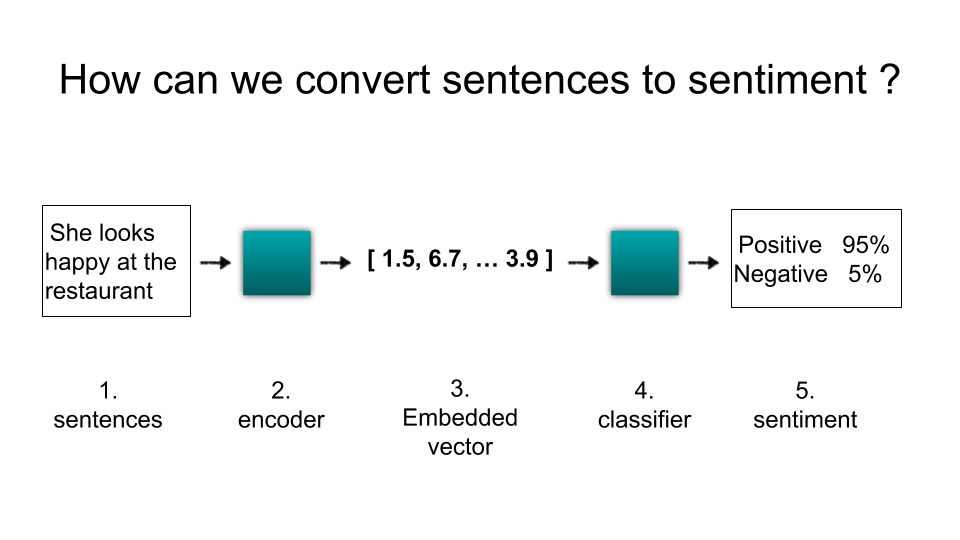 The team in Google claimed that “With transfer learning via sentence embeddings, we observe surprisingly good performance with minimal amounts of supervised training data for a transfer task.”. So let me confirm how it works with a little data. I performed a small experiment based on
The team in Google claimed that “With transfer learning via sentence embeddings, we observe surprisingly good performance with minimal amounts of supervised training data for a transfer task.”. So let me confirm how it works with a little data. I performed a small experiment based on