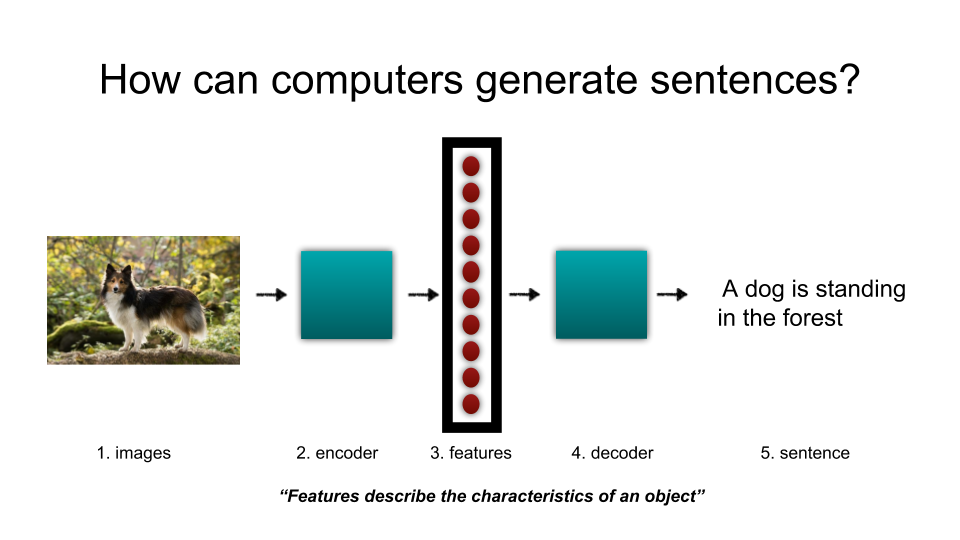
Hi friends. Happy new year! Hope you are doing well. Last year, I found a new computer vision model, called “Stable Diffusion” in September. Since then, many AI researchers, artists and illustrators are crazy about that because it can create high quality of images easily. The image above is also created by “Stable Diffusion”. This is great!
1. I created many kinds of images by “Stable Diffusion”. They are amazing!
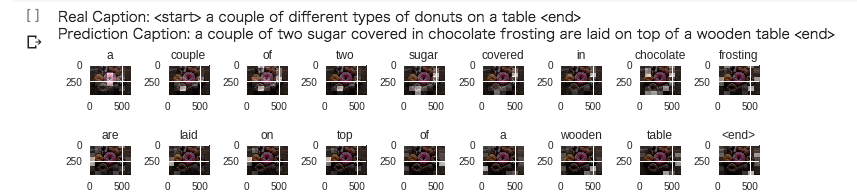
These images below were created in the experiments by “Stable Diffusion” last year. I found that it has a great ability to generate many kinds of images from oil painting to animation. With fine-tuning by “prompt engineering”, they are getting much better. It means that we should input appropriate words / texts into the model then the model can generate images that we want more effectively.

2. “Prompt engineering” works very well
In order to generate images that we want, we need to input the appropriate “prompt” into the model. We call it “prompt engineering” as I said before,
If you are a beginner to generate images, you can start it with a short prompt such as ” an apple on the table”. When you want the image which looks oil painting, you can just add it such as “oil painting of an apple on the table”.
Let us divide each prompt into three categories
- Style
- physical object
- the way the physical object is displayed (ex. lighting)
So all we have to do is to consider what “each category of our prompt” is and input it into the model. For example “oil painting of an apple on the table, volumetric light’ . The results are images below. Why don’t you try it by yourself?

3. More research needed
Some researchers in computer vision think “Prompt engineering” can be optimized by computers. They developed the model to optimize it. In the research paper(1), they compare hand made prompt vs AI optimized prompt (see the images below). Which do you like better? I am not sure optimization always works perfectly. Therefore I think more research is needed with many use cases.

I will update my article to see how the technology is going in the future. Stay tuned!
1) Optimizing Prompts for Text-to-Image Generation Yaru Hao, Zewen Chi, Li Dong, Furu Wei, Microsoft Research, 19 Dec 2022, https://arxiv.org/abs/2212.09611
Notice: ToshiStats Co., Ltd. and I do not accept any responsibility or liability for loss or damage occasioned to any person or property through using materials, instructions, methods, algorithms or ideas contained herein, or acting or refraining from acting as a result of such use. ToshiStats Co., Ltd. and I expressly disclaim all implied warranties, including merchantability or fitness for any particular purpose. There will be no duty on ToshiStats Co., Ltd. and me to correct any errors or defects in the codes and the software.



























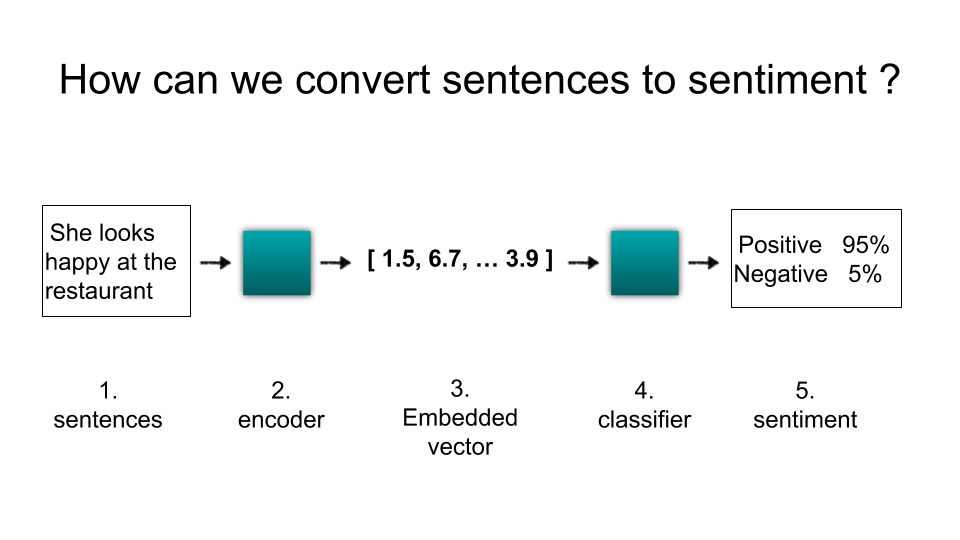 The team in Google claimed that “With transfer learning via sentence embeddings, we observe surprisingly good performance with minimal amounts of supervised training data for a transfer task.”. So let me confirm how it works with a little data. I performed a small experiment based on
The team in Google claimed that “With transfer learning via sentence embeddings, we observe surprisingly good performance with minimal amounts of supervised training data for a transfer task.”. So let me confirm how it works with a little data. I performed a small experiment based on