
Last Sunday, I tried “deep learning” in H2O because I need this method of analysis in many cases. H2O can be called from R so it is easy to integrate H2O into R. The result is completely beyond my expectation. Let me see in detail now!
1. Data
Data used in the analysis is ” The MNIST database of handwritten digits”. It is well known by data-scientists because it is frequently used to validate statistical model performance. Handwritten digits look like that (1).

Each row of the data contains the 28^2 =784 raw grayscale pixel values from 0 to 255 of the digitized digits (0 to 9). The original data set of The MNIST is as follows.
- Training set of 60,000 examples,
- Test set of 10,000 examples.
- Number of features is 784 (28*28 pixel)
The data in this analysis can be obtained from the website (Training set of 19,000 examples, Test set of 10,000 examples).
2. Developing models
Statistical models learn by using training set and predict what each digit is by using test set. The error rate is obtained as “number of wrong predictions /10,000″. The world record is ” 0.83%” for models without convolutional layers, data augmentation (distortions) or unsupervised pre-training (2). It means that the model has only 83 error predictions in 10,000 samples.
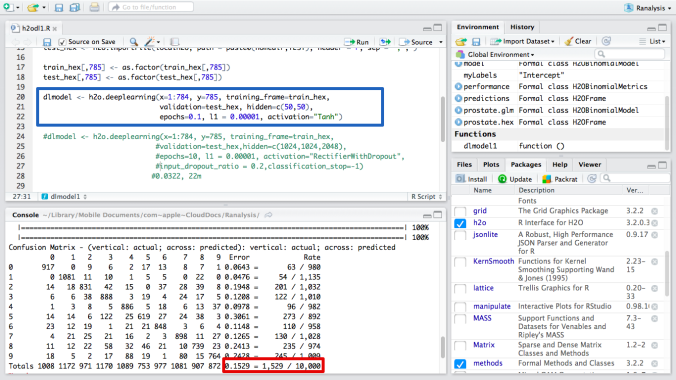
This is an image of RStudio, IDE of R. I called H2O from R and write code “h2o.deeplearning( )”. The detail is shown in the blue box below. I developed the model with 2 layers and 50 size for each. The error rate is 15.29% (in the red box). I need more improvement of the model.
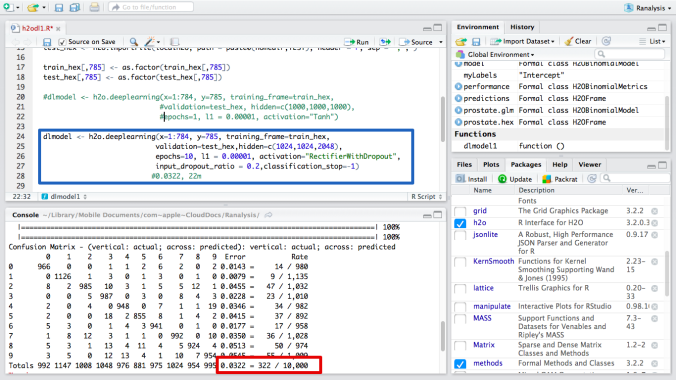
Then I increase the number of layers and sizes. This time, I developed the model with 3 layers and 1024, 1024, 2048 size for each. The error rate is 3.22%, much better than before (in the red box). It took about 23 minutes to be completed. So there is no need to use more high-power machines or clusters so far ( I use only my MAC Air 11 in this analysis). I think I can improve the model more if I tune parameters carefully.
Usually, Deep learning programming is a little complicated. But H2O enable us to use deep learning without programming when graphic user interface “H2O FLOW” is used. When you would like to use R, the command of deep learning to call H2O is similar to the commands for linear model (lm) or generalized linear model (glm) in R. Therefore, it is easy to use H2O with R.
This is my first deep learning with R+H2O. I found that it could be used for a variety cases of data analysis. When I cannot be satisfied with traditional methods, such as logistic regression, I can use deep learning without difficulties. Although it needs a little parameter tuning such as number of layers and sizes, it might bring better results as I said in my experiment. I would like to try “R+H2O” in Kaggle competitions, where many experts compete for the best result of predictive analytics.
P.S.
The strongest competitor to H2O appears on 9 Nov 2015. This is ” TensorFlow” from Google. Next week, I will report this open source software.
Source
1. The image from GitHub cazala/mnist
https://github.com/cazala/mnist
2. The Definitive Performance Tuning Guide for H2O Deep Learning , Arno Candel, February 26, 2015
http://h2o.ai/blog/2015/02/deep-learning-performance/
Note: Toshifumi Kuga’s opinions and analyses are personal views and are intended to be for informational purposes and general interest only and should not be construed as individual investment advice or solicitation to buy, sell or hold any security or to adopt any investment strategy. The information in this article is rendered as at publication date and may change without notice and it is not intended as a complete analysis of every material fact regarding any country, region market or investment.
Data from third-party sources may have been used in the preparation of this material and I, Author of the article has not independently verified, validated such data. I and TOSHI STATS.SDN.BHD. accept no liability whatsoever for any loss arising from the use of this information and relies upon the comments, opinions and analyses in the material is at the sole discretion of the user.
 i
i


















