
At the beginning of this year, I set up a new project of my company. The project is called “Deep Learning project” because “Deep Learning” is used as a core calculation engine in the project. Now that I have set up the predictive system to predict customer response to a direct mailing campaign, I would like to start a sub-project called “DEEP LEARNING PROJECT for Digital marketing”. I think the results from the project can be applied across industries, such as healthcare, financial, retails, travels and hotels, food and beverage, entertainments and so on. First, I would like to explain how to obtain probability for each customer to visit the store in our project.
1. What is the progress of the project so far?
There are several progresses in the project.
- Developing the model to obtain the probability of visiting the store
- Developing the scoring process to assign the probability to each customer
- Implement the predictive system by using Excel as an interface
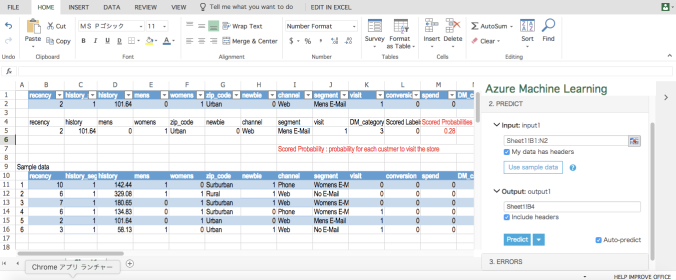
Let me explain our predictive system. We constructed the predictive system on the platform of Microsoft Azure Machine Learning Studio. The beauty of the platform is Excel, which is used by everyone, can be used as an interface to input and output data. This is our interface of the predictive system with on-line Excel. Logistic regression in MS Azure Machine Learning is used as our predictive model.
The second row (highlighted) is the window to input customer data.

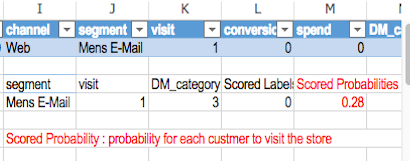
Once customer data are input, the probability for the customer to visit the store can be output. (See the red characters and number below). In this case (Sample data No.1) the customer is less likely to visit the store as Scored Probabilities is very low (0.06)

On the other hand, In the case (Sample data No.5) the customer is likely to visit the store as Scored Probabilities is relatively high (0.28). If you want to know how it works, could you see the video?
2. What is the next in our project?
Once we create the model and implement the predictive system, we are going to the next stage to reach more advanced topics
- More marketing cases with variety of data
- More accuracy by using many models including Deep Learning
- How to implement data-driven management
Our predictive system should be more flexible and accurate. In order to achieve that, we will perform many experiments going forward.
3. What data is used in the project?
There are several data to be used for digital marketing. I would like to use this data for our project.
When we are satisfied with the results of our predictions by this data, next data can be used for our project.
Digital marketing is getting more important to many industries from retail to financial. I will update the article about our project on a monthly basis. Why don’t you join us and enjoy it! When you have your comments or opinions, please do not hesitate to send us!
If you want to receive update of the project or want to know the predictive system more, could you sing up here?
Microsoft, Excel and AZURE are either registered trademarks or trademarks of Microsoft Corporation in the United States and/or other countries.
Notice: TOSHI STATS SDN. BHD. and I do not accept any responsibility or liability for loss or damage occasioned to any person or property through using materials, instructions, methods, algorithm or ideas contained herein, or acting or refraining from acting as a result of such use. TOSHI STATS SDN. BHD. and I expressly disclaim all implied warranties, including merchantability or fitness for any particular purpose. There will be no duty on TOSHI STATS SDN. BHD. and me to correct any errors or defects in the codes and the software.


















